.avif)
Agentic RAG: The Five Retrieval Patterns That Survive Production
Key Takeaways
- Naive retrieve-then-generate RAG looks flawless in a demo and breaks in production, where industry analysis shows naive pipelines failing at the retrieval step roughly 40 percent of the time
- In 2026, retrieval-augmented generation is no longer a feature bolted on to reduce hallucination. It is enterprise AI infrastructure, and the retrieval layer decides whether outputs are accurate, auditable, and economically sustainable
- Agentic RAG wraps retrieval in a reasoning loop, letting the model decompose, route, retrieve, self-evaluate, and re-query until the evidence is sufficient
- Five patterns cover the overwhelming majority of production systems: router, ReAct, plan-and-execute, multi-agent retrieval, and self-RAG, with corrective RAG (CRAG), adaptive RAG, and GraphRAG layered in as the workload demands
- Before any agentic complexity, the foundation is advanced RAG: hybrid search combining dense vectors and BM25, a cross-encoder reranker, and an evaluation harness
- Agentic depth buys accuracy at a real cost, typically 3 to 10 times the token spend and 2 to 5 times the latency, so mature systems route easy queries to a fast path and reserve the loop for hard ones
- A single heuristic governs the build: facts belong in retrieval, behavior belongs in fine-tuning
- Evaluation, not the embedding model, is where most RAG systems quietly fail. Faithfulness, context precision, and answer relevance are the metrics that matter
Introduction: Why Production RAG Is Harder Than the Demo
Most retrieval-augmented generation systems are impressive for exactly one afternoon. The demo answers a clean question against a clean knowledge base, the retrieved passage is obviously correct, and the language model produces a confident, grounded paragraph. Then the system meets a real user, and the gap between a RAG prototype and a production RAG system becomes painfully visible.
Real questions are rarely single lookups. They are multi-part, comparative, ambiguous, or dependent on what was just retrieved. A naive RAG pipeline that embeds the query, pulls the top matching chunks by vector similarity, and stuffs them into a prompt has no mechanism for any of that. It retrieves once, generates once, and hopes. When the first retrieval misses, there is no second attempt, and the model fills the gap with something plausible and wrong.
The shift in 2026 is that retrieval-augmented generation has stopped being a bolt-on enhancement and become core enterprise AI infrastructure. As AI systems move into regulated, revenue-impacting, and mission-critical workflows, the retrieval layer determines whether outputs are reliable, auditable, and economically sustainable. Agentic RAG is the architectural response to that shift. Instead of treating the model as a passive consumer of whatever the vector search returns, it gives the model control over the retrieval process itself.
This guide walks through why naive retrieval breaks, the reasoning loop that fixes it, the advanced-RAG foundation you build first, the five patterns that show up in production, how to choose between them, what they cost, and the evaluation discipline that separates systems that survive contact with real users from systems that quietly degrade.
Why Naive RAG Breaks in Production
The classic RAG pipeline is a straight line with no branches: embed the query, run a top-k vector search, stuff the results into the prompt, and generate. It works for simple factual questions against well-chunked content, and it plateaus quickly. The reasons it breaks are consistent and well understood.
The first is the semantic gap. User queries and document passages often use different vocabulary. A question phrased as how do I cancel my subscription may never match a document titled Account Termination Policy, because pure dense-vector similarity rewards surface-level semantic closeness, not the specific intent. The second is context window pollution. Retrieving ten chunks when only two are relevant dilutes the signal, and the model averages across all of the supplied context, producing a confident but mediocre answer. The third is chunking artifacts. Fixed-size chunks split sentences mid-thought, tables mid-row, and code mid-function, so the retrieved chunk is technically relevant and practically useless.
These are not edge cases. Industry analysis through 2026 consistently shows naive pipelines failing at the retrieval step on the order of 40 percent of the time on anything beyond a basic lookup. The structural weaknesses compound: one shot with no recovery, no decomposition of multi-part questions, no awareness of which source to consult, and no self-check on whether the retrieved evidence actually supports the answer. The fix is not a better embedding model. It is giving the system a way to reason about its own retrieval.
The Agentic Reasoning Loop
Agentic RAG replaces the straight line with a loop. The model decomposes the question, decides what to retrieve and from where, runs the retrieval, judges what came back, and iterates until it has enough to answer. The agent can plan, reflect, and re-retrieve until a stop condition fires.
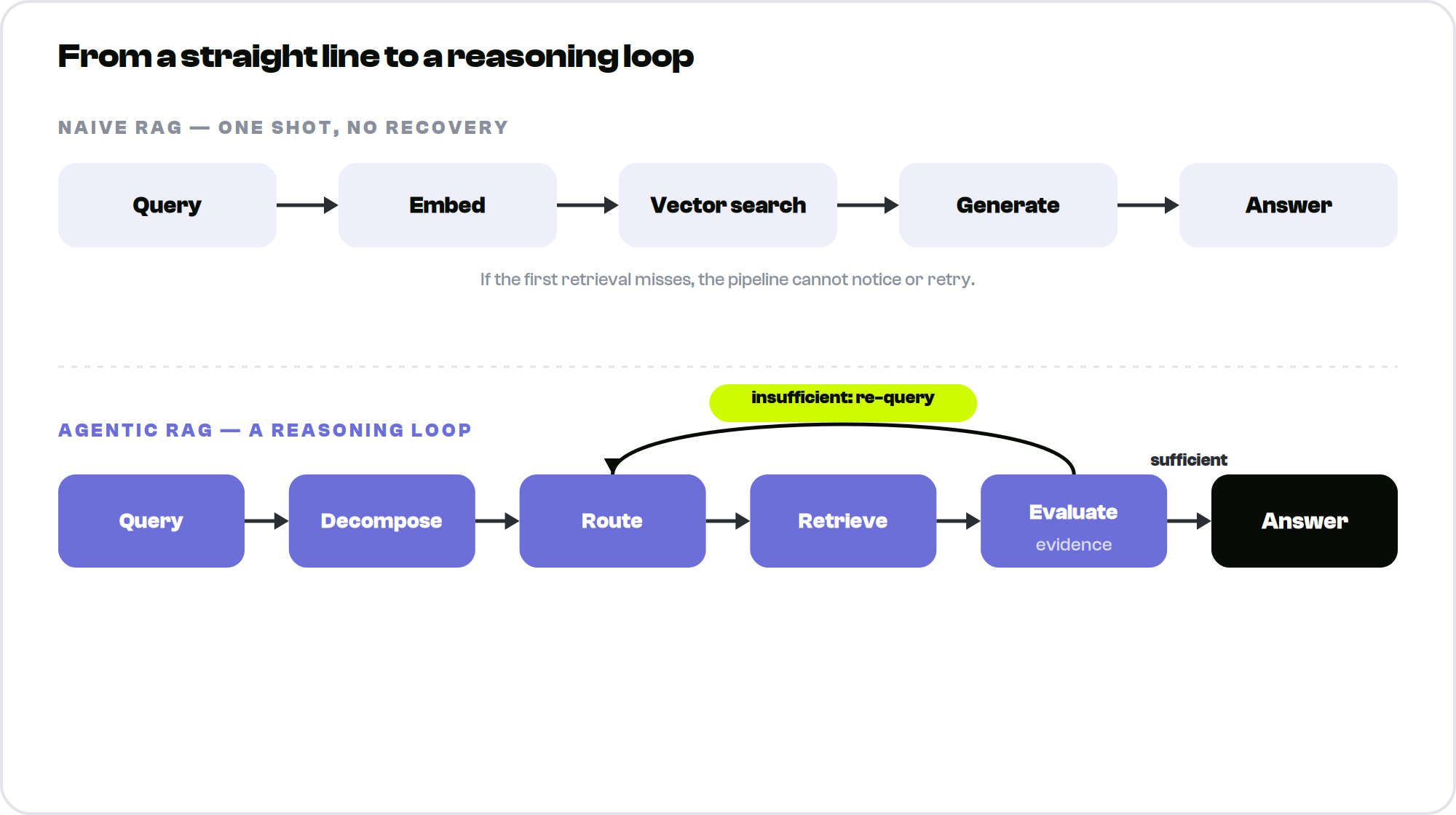
Four capabilities emerge from that single loop. Adaptive retrieval lets the agent decide whether to retrieve at all and which source is appropriate. Multi-step reasoning chains retrievals across a complex question. Tool use lets the agent call databases, APIs, or calculators as part of the process. Self-correction lets it evaluate its own output and try again when the evidence is thin. Naive RAG has none of these because it never makes a decision. The agentic branch consistently wins on hard questions and loses on easy ones, which is the entire reason pattern selection matters so much.
Build the Foundation First: Advanced RAG
The most common and most expensive mistake in 2026 is reaching for agentic orchestration before the underlying retrieval is sound. An agent that loops over a weak retriever simply spends more money to be wrong more elaborately. The production-viable path starts with advanced RAG, and only then adds an agent on top.
The first upgrade is hybrid search, combining dense vector similarity with sparse lexical search such as BM25. Dense retrieval captures meaning; lexical retrieval captures exact terms, names, error codes, and acronyms that embeddings routinely miss. Hybrid retrieval has become the production baseline for accuracy and robustness because it covers both failure modes at once.
The second is a cross-encoder reranker. A first-stage retriever fetches a generous candidate set quickly; a reranker then scores each candidate against the query with far more precision and keeps only the best few. This single step does more for answer quality than almost any other change, because it directly attacks context window pollution: fewer, better chunks reach the model.
The third is embedding model and vector database selection, which set the ceiling on everything above. A strong general-purpose embedding model is the safe default, while the leading open multilingual models now top the public benchmarks for teams that need them. On storage, for most teams under roughly five to ten million vectors, pgvector inside an existing Postgres database is sufficient; purpose-built vector databases such as Qdrant, Weaviate, or Pinecone earn their place when scale, metadata filtering, or latency demands it.
The fourth is chunking strategy. Naive fixed-size chunking is where many systems lose before retrieval even begins. Structure-aware chunking that respects document boundaries, preserves tables and code intact, and attaches metadata for filtering pays for itself immediately. The guiding principle for the whole foundation: implement hybrid search, add a reranker, and instrument evaluation before you add any agentic complexity.
The Five Patterns That Survive Production
Agentic RAG is not one architecture. In practice, five named patterns cover the overwhelming majority of production deployments. They are listed here roughly in order of increasing complexity, latency, and cost.
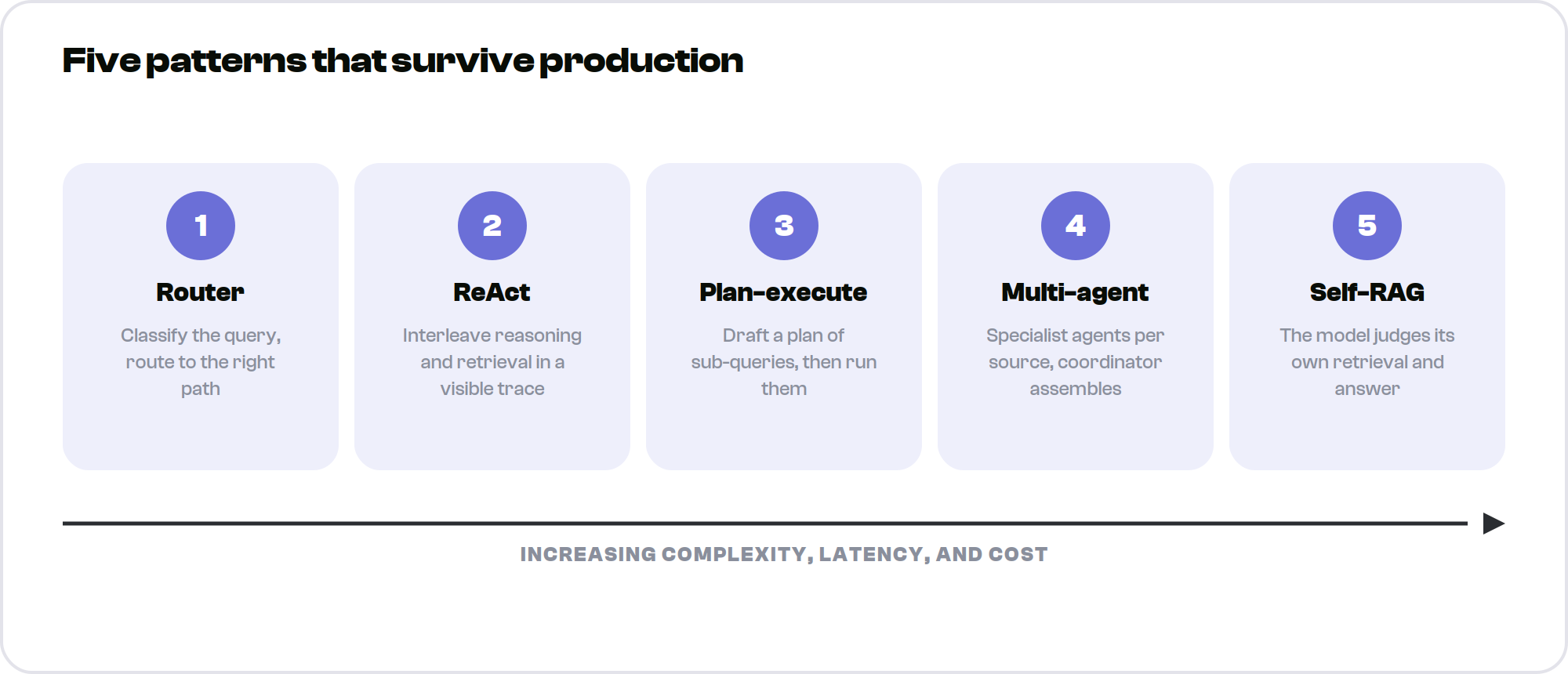
- 1. Router. A classifier inspects the incoming query and sends it down the right path: a cheap vector lookup for simple questions, a heavier pipeline for complex ones, or an entirely different knowledge source. The simplest agentic pattern and often the highest return for the effort, because it is also the mechanism that controls cost
- 2. ReAct. The model interleaves reasoning and action in a visible trace: think, retrieve, observe, think again, retrieve again. It is flexible and transparent, which makes it a strong default when you need to see why the system did what it did
- 3. Plan-and-execute. The agent drafts a full plan of sub-queries, then executes them, sometimes in parallel, before synthesizing. This suits complex, decomposable questions where planning up front beats improvising step by step
- 4. Multi-agent retrieval. A supervisor agent delegates to specialist agents, each owning a domain or a source. One queries the SQL store, another the document index, and the coordinator assembles the result. This is the pattern for genuinely heterogeneous knowledge spread across systems
- 5. Self-RAG. The model emits control signals as it works, judging whether to retrieve, whether the retrieved passages are relevant, and whether its own answer is supported by the evidence. It is the most self-aware pattern and the most demanding to implement well
Three related techniques sit alongside these and compose with them. Corrective RAG (CRAG) adds a retrieval evaluator that grades the retrieved context and triggers a corrective action, such as a web search or a reformulated query, when the grade is low. Adaptive RAG routes by query difficulty, sending easy queries to a fast single-pass path and escalating only hard ones into the loop. GraphRAG structures knowledge as a graph and is best for cross-document, relationship-heavy questions; the most capable 2026 systems often run agentic orchestration over a graph-backed knowledge base.
Choosing a Pattern: A Decision Framework
The most common mistake is reaching for the most sophisticated pattern by default. Complexity is a cost, not a virtue. The decision is not only about query complexity; it is a matrix of complexity, cost sensitivity, latency tolerance, and hallucination tolerance. Walk it as a tree:
- Is the query a single factual lookup?
- Yes → standard retrieval with a reranker. Do not make it agentic
- No → continue
- Does it need a different source depending on the question?
- Yes → Router
- No → continue
- Is it decomposable into known sub-questions?
- Yes → Plan-and-execute
- No, it is exploratory → ReAct
- Does it span genuinely different systems or domains?
- Yes → Multi-agent retrieval
- Is accuracy non-negotiable and worth the latency?
- Yes → layer Self-RAG or CRAG on top of whichever pattern fits
Underneath all of this sits the clearest heuristic in the field: facts belong in retrieval, behavior belongs in fine-tuning. If the system needs current, changing information, retrieve it. If it needs to behave a certain way, in tone, format, or domain vocabulary, fine-tune for it. If it needs both, do both. Many teams reach for fine-tuning when they actually have a retrieval problem, and burn months on the wrong fix.
The Cost and Latency Dimension Nobody Demos
Every step of agentic depth adds latency and spend, and this is the part that never appears in a demo. A vanilla RAG pipeline answers in roughly one to two seconds. An agentic pipeline running three or four retrieval iterations can take eight to twelve seconds, with a worse tail at the 95th percentile. The token economics are starker: agentic patterns commonly run three to ten times the token cost of a single-pass system. At meaningful query volume, a workload that costs a few hundred dollars a day under vanilla RAG can climb into the low thousands per day under unoptimized agentic patterns.
This is why the mature answer is almost never all-or-nothing. The dominant production strategy is adaptive routing: a classifier sends the simple majority of queries through a cheap, fast standard path and reserves the expensive agentic loop for the minority of hard questions that genuinely need it. The main cost levers are well established: tight iteration caps so a loop cannot run away, semantic caching so repeated questions are not recomputed, and adaptive routing so you pay for reasoning only where reasoning changes the outcome. If your product has a sub-three-second latency budget, such as chat, voice, or search-as-you-type, adaptive routing is not optional.
The New Failure Mode: Synthesis Hallucination
Agentic RAG reduces hallucination relative to a single-pass call, but it introduces a failure mode that naive RAG cannot produce: synthesis hallucination. When an agent combines two retrieved chunks that are actually about different things, it can generate a claim that is supported by neither, while looking perfectly grounded. The more sources an agent synthesizes, the larger this risk grows.
The most effective mitigation is citation grounding: require the agent to attribute every claim to a specific chunk by identifier, and flag any claim without a citation for review. This one practice eliminates the majority of synthesis hallucinations because it forces the model to ground each statement in a discrete piece of evidence rather than a blended impression of several. The payoff at the architectural level is large. In a May 2026 MLOps Community benchmark across 47 production deployments, agentic RAG paired with a knowledge graph cut hallucination rates by roughly 62 percent versus naive setups, at the price of added latency and orchestration complexity. That trade is decisive in regulated, high-stakes domains and an unjustifiable tax on a low-stakes FAQ bot.
Evaluation Is Where Systems Quietly Fail
The failure that sinks most RAG projects is not retrieval. It is the absence of evaluation. A team ships a demo that looks brilliant, has no harness to detect regressions, and never learns that retrieval is wrong a meaningful fraction of the time until a user does. The right architecture starts with the evaluation contract, not the embedding model.
Three metrics matter more than any leaderboard score, and frameworks such as RAGAS exist to measure them. Faithfulness asks whether the answer is actually supported by the retrieved evidence. Context precision asks whether the retrieved passages are relevant. Answer relevance asks whether the response addresses the question that was actually posed. Word-overlap scores borrowed from machine translation are not adequate here.
Evaluation has its own trap, sometimes called the evaluator paradox: using an LLM to grade an LLM. The practical mitigations are a frozen golden set of question-and-answer pairs that does not move, ensemble grading rather than a single judge, and periodic human spot-checks to keep the automated grader honest. With that harness in place, the migration from naive to agentic RAG is best done in three increments that each ship independently: add a query classifier up front, add a CRAG-style retrieval evaluator, then add a self-critic on generation. Most teams complete the migration in four to eight weeks and see cost savings from the first step onward, because the classifier alone keeps easy queries off the expensive path.
The Brightter Perspective
The gap between an AI demo and a production AI system is almost always this loop, and the discipline around it. Teams that treat retrieval as a one-shot prompt-stuffing step get a system that impresses in a meeting and erodes trust in the field. Teams that treat retrieval as a reasoning problem, built on a sound advanced-RAG foundation and an evaluation contract, get something that holds up under real questions and real load.
At Brightter, we help organizations move AI from pilot to production by designing the retrieval architecture deliberately: getting hybrid search and reranking right first, matching the agentic pattern to the workload, routing for cost so the economics stay sustainable, grounding citations to control synthesis hallucination, and instrumenting faithfulness and precision before anything ships. The objective is never the most elaborate system. It is the one that stays accurate, explainable, and affordable as the question volume grows.
Conclusion
Agentic RAG is not a trend chasing complexity for its own sake. It is the structural response to a specific, predictable failure: the moment a real question needs more than one lookup. The advanced-RAG foundation, the reasoning loop, the five patterns, the cost-aware routing, the facts-versus-behavior heuristic, citation grounding, and the evaluation contract are the working parts of a retrieval system that survives production in 2026.
If your AI initiative is stuck between a promising prototype and a deployment you can trust, the retrieval architecture is usually where the answer lives. Start a project at brightter.com/start-a-project.